

Tema 9: Datos agrupados en tablas de frecuencias.
Construcción de tablas de frecuencia
Definición de distribución de frecuencias
La distribución de frecuencias o tabla de frecuencias es una ordenación en forma de tabla de los datos estadísticos, asignando a cada dato su frecuencia correspondiente.
Tipos de frecuencias
Frecuencia absoluta
La frecuencia absoluta es el número de veces que aparece un determinado valor en un estudio estadístico.
Al tirar una moneda  veces salen
veces salen  caras
caras
Se representa por  , aunque otros autores la representan como
, aunque otros autores la representan como  .
.


La suma de las frecuencias absolutas es igual al número total de datos, que se representa por  .
.


Para indicar resumidamente estas sumas se utiliza la letra griega  (sigma mayúscula) que se lee suma o sumatoria.
(sigma mayúscula) que se lee suma o sumatoria.

Frecuencia relativa
La frecuencia relativa es el cociente entre la frecuencia absoluta de un determinado valor y el número total de datos.
Se puede expresar en tanto por ciento y se representa por .

La frecuencia relativa es un número comprendido entre  y
y  .
.
La suma de las frecuencias relativas es igual a .



Frecuencia acumulada
La frecuencia acumulada es la suma de las frecuencias absolutas de todos los valores inferiores o iguales al valor considerado.
Se representa por  .
.
Frecuencia relativa acumulada
La frecuencia relativa acumulada es el cociente entre la frecuencia acumulada de un determinado valor y el número total de datos.
Se puede expresar en tantos por ciento.
Ejemplo:
Durante el mes de julio, en una ciudad se han registrado las siguientes temperaturas máximas:

 .
.
En la primera columna de la tabla colocamos la variable ordenada de menor a mayor
En la segunda hacemos el recuento
En la tercera anotamos la frecuencia absoluta
En la cuarta anotamos la frecuencia acumulada:
En la primera casilla colocamos la primera frecuencia absoluta:
En la segunda casilla sumamos el valor de la frecuencia acumulada anterior más la frecuencia absoluta correspondiente:

En la tercera casilla sumamos el valor de la frecuencia acumulada anterior más la frecuencia absoluta correspondiente:

La última tiene que ser igual a (sumatoria de ).

En la quinta columna disponemos las frecuencias relativas  que son el resultado de dividir cada frecuencia absoluta por
que son el resultado de dividir cada frecuencia absoluta por 
En la sexta anotamos la frecuencia relativa acumulada  .
.
En la primera casilla colocamos la primera frecuencia relativa acumulada.
En la segunda casilla sumamos el valor de la frecuencia relativa acumulada anterior más la frecuencia relativa correspondiente y así sucesivamente hasta la última, que tiene que ser igual a .
 |
Recuento | |
|
|
|
|---|---|---|---|---|---|
 |
I | |
|
 |
|
 |
II |  |
 |
 |
 |
 |
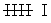 |
 |
 |
 |
 |
 |
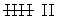 |
 |
 |
 |
 |
 |
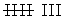 |
 |
 |
 |
 |
 |
III | |
|
|
 |
 |
III | |
|
|
 |
 |
I | |
|
|
|
|
|
Este tipo de tablas de frecuencias se utiliza con variables discretas.
Distribución de frecuencias agrupadas
La distribución de frecuencias agrupadas o tabla con datos agrupados se emplea si las variables toman un número grande de valores o la variable es continua.
Se agrupan los valores en intervalos que tengan la misma amplitud denominados clases. A cada clase se le asigna su frecuencia correspondiente.
Límites de la clase
Cada clase está delimitada por el límite inferior de la clase y el límite superior de la clase.
Amplitud de la clase
La amplitud de la clase es la diferencia entre el límite superior e inferior de la clase.
Marca de clase
La marca de clase es el punto medio de cada intervalo y es el valor que representa a todo el intervalo para el cálculo de algunos parámetros.
La marca de clase se representa por 

Construcción de una tabla de datos agrupados
 .
.
1º Se localizan los valores menor y mayor de la distribución. En este caso son y  .
.
2º Se restan y se busca un número entero un poco mayor que la diferencia y que sea
divisible por el número de intervalos queramos establecer.
Es conveniente que el número de intervalos oscile entre y  .
.
En este caso,  , incrementamos el número hasta ,
, incrementamos el número hasta ,  intervalos.
intervalos.
Se forman los intervalos teniendo presente que el límite inferior de una clase pertenece al intervalo, pero el límite superior no pertenece intervalo, se cuenta en el siguiente intervalo.
es la marca de clase que es el punto medio de cada intervalo.
|
|
|
|
|
|
|---|---|---|---|---|---|
 |
 |
|
|
 |
|
 |
 |
|
|
|
 |
 |
 |
|
 |
 |
 |
 |
 |
|
|
|
 |
 |
 |
|
 |
|
 |
 |
 |
|
 |
 |
 |
 |
 |
|
|
 |
 |
 |
 |
 |
|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
|
 |
|
|
|
1 |